A process to semi-automate research using few-shot classification and GPT-4 summation
I run a discussion group in which I and others talk about a wide variety of topics. Tomorrow I am going to be talking about Jonathan Haidt’s book The Anxious Generation, and give my own views on how to use social media and the web in a productive and healthy way.
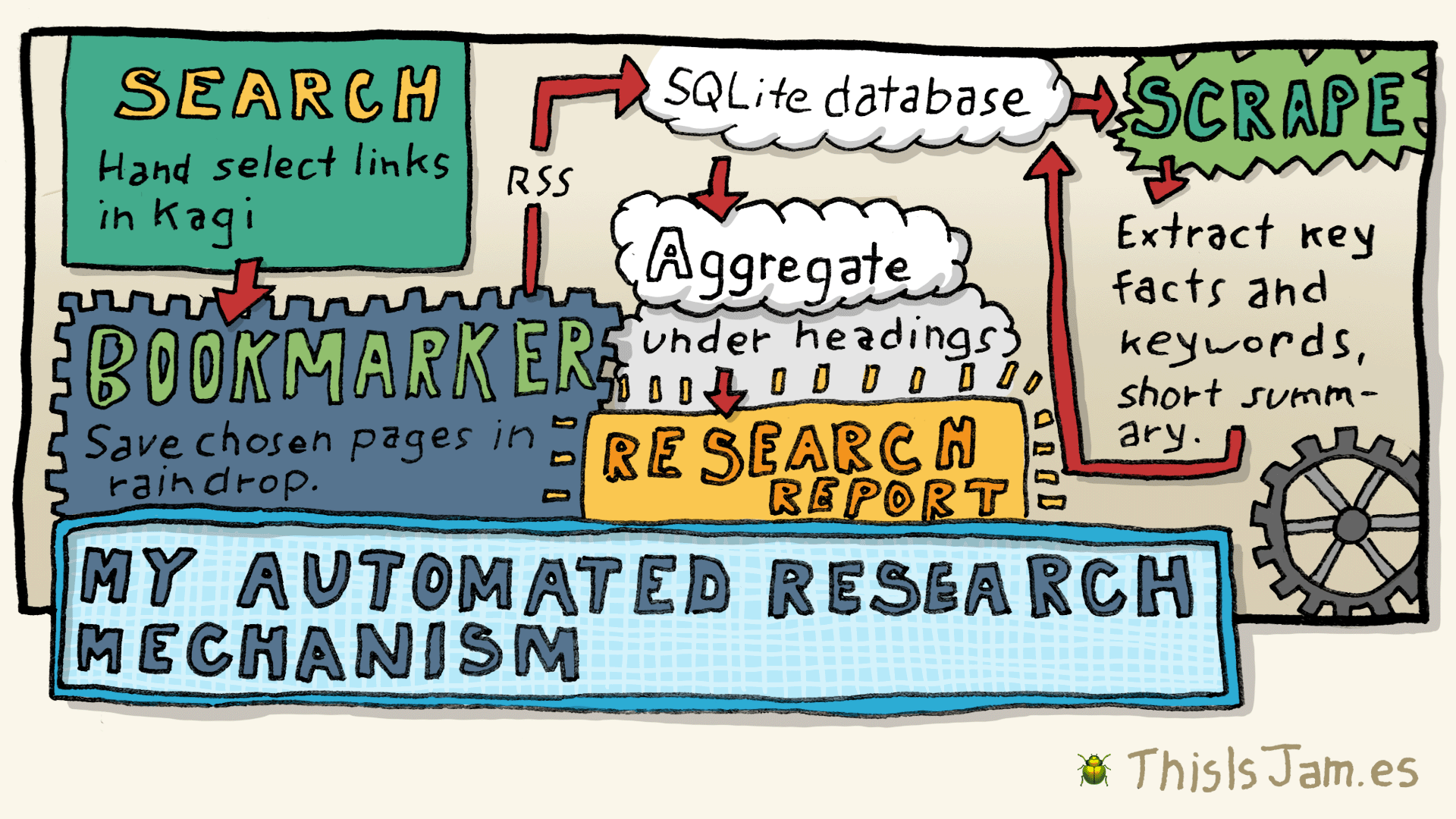
How I research
Apart from reading books, I research using online articles and news. This is especially good for topics that are current and changing. I have various sources that I check for articles (I’ll document that another day), and I also use the Kagi search engine.
Kagi
I’ll do various searches on Kagi on a topic, then open any links I think look interesting in new browser tabs. Then I’ll quickly go through all those tabs, and if the article looks good, I’ll save it in my bookmark manager.
I use Kagi for search for the following reasons:
- Google Search has become increasingly bad over the years, and often doesn’t return good results. It is also too full of advertisements.
- I think Google has too much power now and I want to support other options. Google is damaging independent publications and bloggers, and it would be a great shame if we lost those.
- Kagi results are really nice — no advertisements, configurable, and you can focus on specific sources, such as news or academic sites.
I pay 54 USD1 a year for Kagi, which I’m happy to do for a tool I use every day.
1 I may need to move to their next pricing tier ($108/yr) because I think I’m using more than 300 searches per month. Kagi pricing.
Raindrop: Bookmark manager
If I come across an article online related to a subject I am interested in, I will save it in my bookmark manager, Raindrop. I use it for the following reasons:
- It has good browser extensions, including for Safari, which is my main browser.
- It is reasonably priced (27 EUR a year ex VAT).
- You can create folders for bookmarks and share them publicly, and allow others to add and edit the list. This is the main reason I like it, because it allows me to share bookmarks with my discussion group.
- You can export a folder as RSS, and various other formats including CSV, which includes parts that you have highlighted.
It’s not perfect. You can highlight pages and attach notes, but that functionality doesn’t work as well as I would like. But it’s pretty good all round. I used to use pinboard.in, which is a bit more basic but also pretty good.
Whilst I’m talking about tools and services I use, I’ll mention another one which I’ll talk about later on in this process:
Jina Reader
The wonderful Jina Reader has a very simple API to do something very useful — it will give you a markdown version of any web page. They give you one million tokens to do this for free, which I estimate will give you about 400 free URL lookups. A great service, which I won’t mind paying for once I run out of tokens. Python God Simon Willison made a little online interface to Jina which might be a useful addition to your browser toolbar.
Semi-automating my online research process
So at the moment I have a Raindrop folder called “Anxious Generation” where I put news items and articles related to that subject. There are currently 69 bookmarks in the folder. I’ll have read some, but not all, of those articles. When I’ve done this previously I have spent several hours going through all the articles when I am preparing my talk, but I want to make that process more efficient, so I only read the better and more interesting articles. That is what I am going to now.
Step 1: reading the CSV export into an SQLite table
I was originally planning to read from the RSS feed, because I thought this would be a better process because I could make automatic updates whenever I add a new bookmark to the list. But there is an issue — the RSS feed does not contain highlights or notes. I guess I could potentially use a combination — RSS for automatic updates, and then CSV when I want highlights etc. added. But I’ll just use the exported CSV for now.
So first I want to use a command line process to import the CSV file into my personal SQLite database. I’ve looked at the CSV file and there is some funny stuff going on in there with quotes, but let’s just try importing and see what happens.
sqlite-utils insert research.db anxious_generation anxious_generation.csv --csv --pk id Ok, that worked. Note that the CSV file has an id column. Setting –pk=id makes that the key column, so sqlite-utils won’t import a record if it has already been imported. This is useful if you want to update your table with new records.
I’ll add a column to include the contents of the article in Markdown:
sqlite-utils add-column research.db anxious_generation markdown textI also converted the id column, which contains a number, from integer to string:
sqlite-utils transform research.db anxious_generation --type id integerStep 2: get the content of the web pages in Markdown format
Now I want a Python script that does the following:
Use Python click to get a value for tablename variable.
Loop through all the rows in the table anxious_generation in the database research.db
* if column `markdown` is not NULL or an empty string, continue.
* if column `url` contains `youtube.com` , continue.
* Get the response from the URL `https://r.jina.ai/[url]`
* Remove everything in the response up to and including the line `Markdown Content:` and put that string into the column `markdown`.I discovered on first use that the Jina service has rate limiting, which is fair enough:
429 Client Error: Too Many RequestsSo I found out what the limit is and added a pause of four seconds between each call to the service. It works really well, now I have a table containing all the content from the pages in Markdown format. Very satisfying.
Ok I’ve spotted some issues. The following sites do not return content to Jina:
- Reuters
- archive.is
- Twitter/X
I use archive.is links a lot because it makes accessing content consistent. For the moment I’m going to do these links “by hand” using the MarkDownload Safari extension. (It only took a few minutes but I’d like to do it automatically in the future.
Step 3: Get the source URLs if an intermediary URL is given
I want to get the source URL from the Markdown content if it isn’t in the URL in the RSS feed. As this is a fairly simple task, I’m going to try using GPT-4o mini for this task, as it is cheap, currently $0.150 / 1M input tokens, $0.600 / 1M output tokens. Here are a few basic notes I made on Using the OpenAI API.
To do this I’m going to start a new Python script. It needs to do the following:
Use click to get a value for tablename variable.
Loop through all the rows in the table tablename in the database research.db
* Get the value of the `markdown` and `url` columns.
* If column `markdown` is NULL or an empty string, continue.
* if `url` contains `archive.is` send the following prompt to OpenAI GPT-4o mini:
Return the source web domain for the attached content. Do not return
anything else other than the source domain. Here are some examples of
how to get the source domain:
If the markdown contains a link like this:
https://archive.is/o/Ebwt6/https://www.thesaturdaypaper.com.au/news/politics/2024/08/10/esafety-commissioner-we-are-testing-our-powers
return: https://www.thesaturdaypaper.com.au/
If the markdown contains a link like this:
https://archive.is/o/WKJVO/https://www.economist.com/printedition/2024-01-27
return: https://www.economist.com/
If the markdown contains a link like this: https://archive.is/o/E9ZvN/
https://www.ft.com/content/9d9830cb-aeca-4dd7-aeba-fc9385a4796c
return: https://www.ft.com/
* Put the returned value in the `source` column.
else
Put the value of `url` in the `source` column.Step 4: Remove all the crap from the extracted Markdown to just leave the content
Whilst Jina does a good job getting all the content from pages, it also gets all the navigation links, advertisements, and other crap. I want to see if I can clean it up using one of the cheaper options. To do this I’m going to start a new Python script. It needs to do the following:
You are a Markdown content extraction assistant specializing in extracting clean article text from web pages saved as Markdown files. Your task is to extract only the main body text of the article while keeping Markdown formatting intact.
Instructions:
1. Include:
• The article’s title and main content, including headings, paragraphs, lists, blockquotes, and inline formatting such as *italic*, **bold**, and > blockquotes.
2. Remove:
• Navigation menus, site headers, footers, advertisements, and user comments.
• All links in the returned text, leaving only the link text.
• Media references such as images, videos, and embeds.
• Social media sharing buttons, subscription links, and other calls to action.
Here is the markdown to process:That works pretty well! Although it’s slow. It will be interesting to see the cost of processing about 60 links like this. I’m waiting for it to finish… It seems to have cost about 0.10 USD. If that’s how little it costs to do this stuff a world of possibilities awaits…
Abandoning this process due to a better idea
Whilst developing this process I realised that I could come up with a much simpler, better process. The problems with this process are:
- Getting the markdown of a web page using Jina returns a lot of crud, which then needs to be removed. Wouldn’t it be better to use a process that starts with fairly clean markdown?
- Using a process like this means that I could potentially create my own bookmark listing pages automatically, rather than using the ones created by Raindrop. If if can do that, then do I really need Raindrop, especially considering that ones I can make myself will be much more flexible? Also I can use the processes I have already developed to generate web pages from Bear App.
- Safari, which I use as my main browser, already has a neat method to clean a lot of the crud of web pages away — Reader mode. Why don’t I use that to preprocess web pages before sending them to Bear? Unfortunately the Bear Safari extension doesn’t take the page generated in Reader mode (apparently extensions or Javascript cannot access the generated content) but you can ⌘a to select all text, and then ⌘b (which Bear App automatically sets up) will send the selected text to Bear. It works!
It always feels like a bit of a waste of time doing stuff and then abandoning it, but of course that isn’t the case — you have to experiment, and you’re not experimenting if you’re not failing fairly often.
I am working on my better process idea and will create a new post when I have finished it.